


网络服务
知识库构建注意事项
在给定知识库的问答智能体中,好的问答效果除了模型能力、提示词外,知识库的质量是觉得问答效果的重要组成部分,怎么让AI更好的理解你给的知识,是知识库构建中的核心。
一般影响知识库效果的内容包含文件本身、分段、检索参数以及模型参数四个部分。
1.知识库文件本身
1.1.文件格式
(1)文件最好是markdown格式(文件后缀名为.md)md格式对表格、公式、图片等复杂格式支持的最好,可以将doc、pdf的文件使用软件转化为md这里不建议用在线转化的工具转化,涉及信息安全;最好用可下载到本地的软件进行转化(如Writage、pandoc、doc2x)。
(2)其次最好是可编辑的doc、txt格式。
(3)最好不是带杂乱数据的pdf,尤其是带许多页眉页脚页数等脏数据的pdf(如下图),尤其是低分辨率又占不少内存的容易被识别成图片的pdf。
(4)ppt格式的可以传,但不推荐。
(5)excel格式的数据/表格数据要按下下图所示排列,按标准数据库的格式排列,第一行一定要有表头(学号、姓名、年龄等),否则大模型也不知道这一列代表什么,一行就是一条记录,一列就是一个字段。

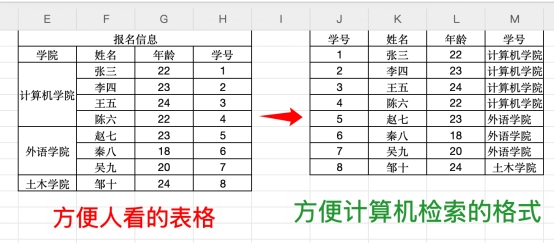
补充:牵扯复杂结构(如表格、公式)数据,建议重整成markdown格式的文档,目前有一些网站有免费额度转化,可以在网页或下载他们的客户端使用,不过要注意数据安全问题。
1.2.文件组织
(1)最好是逻辑上结构化的,按章节的逻辑排列(如有)。
(2)每个“知识点”附近要有对应的关键词的(这个方便模型去匹配提问),不然孤零零的一段是没法匹配到的。
(3)甚至可以预设一些提问放进答案附近,这样能更好的匹配到这个“知识点”,但是要不要这么做看实际情况,大模型的理解能力还是很强大的,放进去测试一下多试几种问法再看。
1.3.文件集合
涉及多文件,最好按类别分知识库建立,例如规章制度类的建立一个知识库,并且知识库的名字一定要起对应的名字,方便检索。
2.分段设置
大模型在试用知识库中的内容时会将内容拆分成独立段落作为单独的知识点理解、检索,分段的质量也会影响大模型理解、检索的效果。
我们在上传文件的时候有一个分段方式设置,所谓分段方式就是将一个文件按照一定的逻辑分成几段,分好段后模型会根据用户的提问去匹配某个(或某几个)最接近提问的分段。至于是匹配几个就是“最大召回数”这个参数,后文会交代。
分段后可以看到具体文件的分段详情:

分段过程中可能会将一个完整的章节段落拆分到不同的分段中,这样就很可能导致被切掉的另一部分没被匹配到,导致回答的不全,如果被切断的部分本身与提问的字眼没有强的相关性,就可能没模型忽略掉。
要优化这个问题,有两种解决方案:
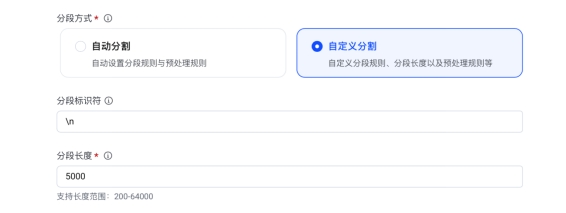
1、提高每个分段的字符数,相当于减少被切的段数。
这个可以通过自定义分段的方式实现,分段长度适当放大,例如4000, 但是这个分段也不宜过大,会影响每一次检索的性能,比如如将这个值设置为10000,召回分段数设置为10, 相当于大模型每次就要处理10000*10=10w字符的数据,当然大模型有这个能力,不过就是浪费算力。
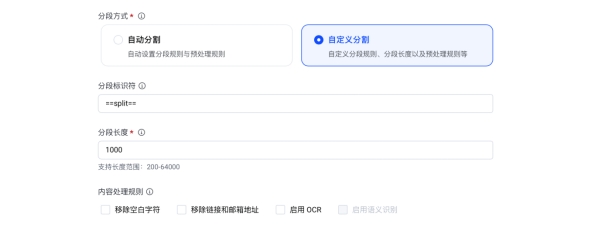
2、手动通过加入分段符的方式去分割。
例如这是一份电子邮箱服务介绍,我们可以根据逻辑,将电子邮箱的介绍和邮箱升级能力中间加一个“==split==”分割符进行分割。

除了在文件内加入分割符,还要在分段方式里设置此分段标识符(这个分割符不唯一,只要和文件内的统一就好了,不过也要注意不要和文本内容相同)。
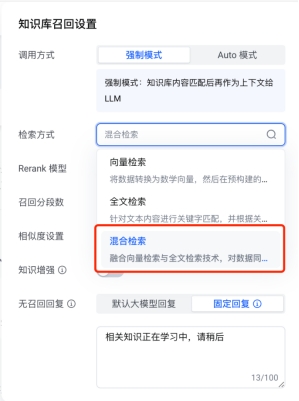
3.检索参数
3.1.检索方式
这里不推荐选全文检索(传统的检索方式),向量检索跟混合检索二选一,向量检索是根据语义相似度进行匹配,规章制度类文本数据可以选择向量检索,如果向量检索找不到知识库内的数据,可以尝试选择混合检索(综合向量和全文检索),尤其是Excel表格类的数据,如果提问某个表格中“人事处XXX办公室所有人员的姓名”,如果使用向量检索,他会去向量数据库匹配“人事处XXX办公室所有人员的姓名”,那么很可能匹配不到,这个时候我们就要选择混合检索,通过全文搜索的能力,再进行整理效果会好。

模型可以选择默认模型。
3.2.最大召回数
用户提问是,模型会将提问的内容与向量数据库中匹配,(所谓向量数据库就是通过分段后再向量化的数据库),最大召回数就是最多返回与提问最接近的分段的数量,我们可以通过下图的提问测试中的找到了多少个来源体会这一点,
例如,这里的最大召回数设置为11,每次的回答它会返回不超过11条的来源,这里是10条(是因为只找到了10条)。
平台默认的数量为3,意味着返回不超过三条最接近的数据,太少,这个就很影响大模型的总结。
这里要多给大模型一些参考数据,一个参考值可设为10,不过这个数值越大性能消耗越大(与前文陈述的那个分段长度相关)
3.3.相似度
这个参数指的是用户提问与知识库(向量库)的内容匹配时,要求的接近程度,相似度要求越高,返回的答案越精准,当然过高会找不到答案;相似度越低,返回的答案越模糊,找到相关内容的可能性就越高。
这个参数的设置按默认的0.5做参考,调高调低根据应用的需求而定,也跟知识库本身的编写有关,如果知识库章节之间独立性较高,设置相对高的相似度可以更有针对性的匹配相关内容。
4.语言模型参数
预研模型参数在调试与预览中点击模型选择按钮进行设置。
配置项 |
说明 |
随机性temperature |
•采样温度,控制输出的随机性,值越大会使输出更随机,更具创造性;值越小,输出会更加稳定或确定 |
核采样top_p |
•控制输出的多样性,值越大输出包括更多单词选项;值越小,输出内容更集中在高概率单词上,即输出更确定但缺少多样性。一般temperature和top_p只设置一个 |
单次回复max_tokens |
•单次输出内容最大token数 |
对话轮数保留 |
•带入模型上下文的对话历史轮数。数值越大,多轮对话内容的相关性越高,但消耗token数也更高 |
RAG范围 |
•开关:打开时携带历史对话的问题和答案,关闭则表示只包含问题 •知识库检索场景带入向量检索的历史对话轮数(只包括问题)。数值越大,多轮对话内容的相关性越高,但消耗token数也更高 |
思维方式 |
•如果切换后的模型不支持FC模式,则智能体会按照React模型运行,并且切换成React模式 |
迭代次数 |
•设置智能体执行迭代的次数,数值越大可能导致运行时间过长 |

地址:陕西省西安市咸宁西路28号 邮编:710049
版权所有:西安交通大学
站点建设与维护:网络信息中心 陕ICP备06008037号-5 陕公网安备61010302001223